-
In your manual, you said that MPI_COMM_WORLD is the communicator if no custom is provided. Does precice really use MPI_COMM_WORLD or do a MPI_Comm_dup on MPI_COMM_WORLD? If precice does duplicate, it doesn’t matter a communicator is specified or not, right?
-
According the name “m2n” and the following manual, if I do a FSI simulation using MPI, I think the fluid solver and the solid solver can have their own communicators. My understanding is that PRECICE will have another communicator. So at least, there can be 3 communicators in this FSI run. Is this true?
-
For the fortran interface, it appears that the communicator is not on the argument list. My guess is that you might do a MPI_Comm_dup in my question1. So it doesn’t matter to specify the communicator or not, right?
-
According to the following information, OpenFOAM is using OpenMPI, does this mean that when I build PRECICE, I also need to use OpenMPI? And for our own solid solver, we also need to use OpenMPI to build, right?



Hi @hongwuw,
it’s generally better to split questions into multiple topics to keep searchability high and make them easier to discuss.
Regarding your questions:
- preCICE uses MPI_COMM_WORLD or the passed communicator without further modifications.
- Fluid and Solid are started separately and have their own
MPI_COMM_WORLDcommunicators. preCICE establishes an intercommunicator between these two runs using MPI_Comm_accept and MPI_Comm_connect. This leads to a total of 4 comms, two on each side. Also note thatm2n:socketsis a more robust and sufficiently performant choice until you run on very large systems. - That’s correct. We have been struggling to figure out how to pass a communicator via the interface. We decided to ignore this as there was no demand. Ivan Pribec did some leaps in extending the Fortran interface.
- Short answer: Yes and it depends.
Long answer: It is a general requirement that libraries are unique in the entire dependency graph of an executable. Mixing versions and implementations leads to race conditions that lead to obscure and difficult to debug errors. A good guideline is to use system-provided libraries if they are available, and something like spack if you need different versions. This is particularly difficult to handle when the solver provides its own dependencies, which is common for commercial codes. If the MPI implementation of OpenFOAM is OpenMPI, then preCICE must either use the same implementation and version, or be build without MPI.
Different configurations of preCICE can be compatible, so you can couple a solver using MPICH and another solver using OpenMPI by compiling two different preCICE configurations of the same preCICE version. You must use<m2n:sockets ... />in this case though.
Hope that helps
Frederic
Hi @fsimonis,
Thanks a lot for your answers. They really help lot on the understanding for our own adapter to Precice. Regarding your point 2, if I have the following runs:
mpirun -n 10 solidSolver
mpirun -n 20 fluidSolver
solidSolver and fluidSolver have their own communicators, for example, solidComm and fluidComm to handle their own processes. You said there would be 4 comms in total. I think besides solidComm and fluidComm, Precice will generate the remaining 2 comms. If I say they are named as preciceSolidComm and preciceFluidComm, do you mind shedding more lights on how many processes they are going to have? I guess that there will be inter-communications between solidComm and precicieSolidComm and the same for fluid solver side.
Back to my 1st question, for the argument “&my_comm” in your precice function call, I guess my_comm is basically the solidComm in my above example, right? And Precice needs this comm to setup the inter-communication between solidSolver processes and Precice processes, right? (The reason I am asking is because our solver doesn’t use the default MPI_COMM_WORLD communicator, instead we do a duplicate and use this duplicate to avoid conflicting with external libraries).
That is we need to use this duplicate (out of MPI_COMM_WORLD) as the argument to the precice function call for the inter-communication between our solver and Precice successfully, right?
Regarding the above statement, if precice is built without MPI, while solidSolver and OpenFOAM are built with MPI and are run by mpirun, this case should also work perfectly if I understand correctly.
And for this case, should both solidSolver and OpenFOAM enforce the following to have the non-MPI Precice? Or one side non-MPI Precice is ok?
rank = 0
commsize = 1
CALL precicef_create(participantName, config, rank, commsize)
My understanding on the above is that for example, the solidSolver can use MPICH while OpenFOAM can use OpenMPI. But requirement is the solidSolver is linked to an MPICH-linked/complied-Precice. OpenFOAM is linked to an OpenMPI-linked/compiled-Precice. Both Precices need to be the same version.
Thanks
Hongwu
Can the following case work?
xMPI-solidSolver + non-MPI-Precice.so <=> yMPI-Precice.so + yMPI-OpenFOAM
meaning:
x, y: different MPI, i.e. intel-MPI, OpenMPI etc.
+: linking
<=>: mpirun -n 10 solidSolver ; mpirun -n 20 OpenFoam
Your solidSolver has an MPI_COMM_WORLD of 10 ranks. Assuming that the solver is calling MPI_Init before constructing a preCICE Participant, then preCICE will use that communicator (MPI_COMM_WORLD or the comm passed via the constructor) internally as “externally managed”. So it just uses it without further modification or duplication.
If you use <m2n:mpi /> the solidSolver will create an intercommunicator based on this communicator.
Have a look at the code for more detail: precice/src/com/MPISinglePortsCommunication.cpp at develop · precice/precice · GitHub
Yes
You can pass it via the interface if you like.
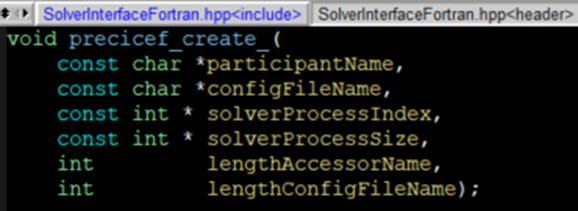
In such a case you need to define a custom intra comm:
This is up to you. The only requirements are that all libraries in an executable are unique and that preCICE needs to use the same MPI library on both sides if you want to use <m2n:mpi />.
If your solver uses MPI and runs on 4 ranks, then rank 0 would call with rank=0 and commsize=4.
preCICE doesn’t need to use MPI. It can use an intracomm based on sockets for internal communication. Important is only that preCICE knows which rank it is.
Correct.
Yes. Only limitation is that this prevents you from using mpi related m2n functionality.
Hi, @fsimonis, thank you so much. I really appreciate your patience to clearly answer all my tedious questions. ![]()
for the following case:
xMPI-solidSolver + non-MPI-preCICE.so <=> yMPI-preCICE.so + yMPI-OpenFOAM
mpirun -n 10 solidSolver
mpirun -n 20 fluidSolver
to make this case work (MPI-solidSolver linked with non-MPI-preCICE.so), my summary based on your explanation is:
- only use m2n:sockets
- use intra-comm:sockets for the participant solidSolver.
- But the participant fluidSolver shouldn’t use intra-comm:sockets
- on the side of solidSolver, CALL precicef_create(participantName, config, rank=0, commsize=10) so that the non-MPI-preCICE knows it is rank 0 of solidSolver to do an intracomm internal to preCICE.
when I ran the above case:
xMPI-solidSolver + non-MPI-preCICE.so <=> yMPI-preCICE.so + yMPI-OpenFOAM
I got the following error. Why “a serial participant” when “mpirun -n 10 solidSolver” is used? I attached my configuration xml file here.
precice-config.xml (1.9 KB)

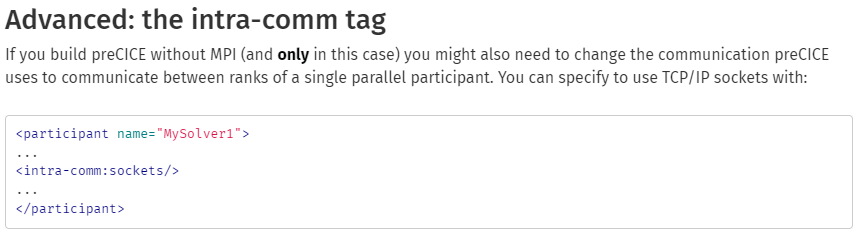
If I have 2 participant, A and B. A is run with m processes and B is run with n processes.
-
<m2n:sockets …/>: My understanding is that this type of communicates only through A’s root with B’s root through a sockets.
-
<m2n:mpi …/>: My understanding is that this type of communication can happen for any process of A with any process of B.
Please correct me if I am wrong.
Then, I want to focus on the method of m2n:sockets. If A is linked with non-MPI-preCICE.so, does this mean that preCICE will only use rank 0 for both communications to the other solver B and mapping calculations?
And the other question is that for this case, “A is linked with non-MPI-preCICE.so”, because A is run with m processes while preCICE is not linked to MPI and so preCICE dosen’t know MPI is running, A itself is responsible to collect and scatter information to rank 0, then call precicef_write_bvdata and precicef_read_bvdata to talk to preCICE, then preCICE will do its job (for example mapping) on process 0 and then talk to B through a sockets. Is this correct?
Thanks a lot
If I focus on m2n:sockets and use it only, if both A and B linked with MPI-preCICE.so, you said there would be 4 communicators: A has 2 and B has 2, is this correct? For the side A, can I say that one communicator is for solver A itself and the other communicator is for preCICE? Between these 2 communicators, they talk through inter-comm, right? But from the side A to the side B, they talk using sockets? If this is the case, side A and side B can have MPI from different vendors and different versions?
Thanks
Hi, this means that you are incorrectly passing a size of 1 to the constructor of Participant, while you are running your solver with 10 ranks. Ranks and size must match between MPI and preCICE! That’s mentioned repeatedly in the docs.
This is a fully parallel m-to-n (hence the name) communication. You can enable a gather-scatter mode in which case all communication goes thought the connection between the primary ranks (0) of both A and B.
This also answers the followup question.
Not sure if I understand your question.
preCICE has to know its parallel context. Let me give you 3 examples:
- Your solver is a single process and uses multiple GPUs or OpenMP to compute something. Then the process creates a
Participant(.. ,0, 1)as there is only one instance of this solver. - Your solver is a single process, that spawns 12 subprocesses. Each of these subprocesses creates its preCICE participant. Then the subprocess of index i \in [0; 12) creates
Participant(..., i, 12). - Your solver uses MPI and is spawned using 12 ranks, Then the preCICE participant is created with
Participant(..., rank, size)where rank and size corespond toMPI_COMM_WORLD.
Further communicators are only necessary if you use <m2n:mpi />. If you use <m2n:sockets/>, then there will be no further communicators.
If you use <m2n:sockets/>, then these two solvers only talking to each other via the TCP communication backend of preCICE.
If you use <m2n:mpi/>, then these two solvers talk to each other via MPI (which can be many things including TCP), but both sides need to establish a communication which requires a compatible MPI implementation. If you like to know more about further limitations or details, then I kindly forward you to the MPI standard and the documentation of the various MPI implementations.
The bottom line is:
If you want to use
<m2n:mpi/>you need the same MPI on both solvers.
Actually, that error was triggered when I ran in the way of “mpirun -n 1 solidSolver”. So preCICE treats this case as a serial participant.
so for this case, can I understand in the way that there are only 2 communicators in total from both side A and side B (the 4 communicators case is only for m2n:mpi), right?

The opposite to the above manual description is "if I don’t specify a specific port, for m2n:sockets, preCICE will use multiple ports to communicate and hence no need to enforce gather-scatter?
xMPI-solidSolver + non-MPI-preCICE.so <=>
- mpirun -n 1 solidSolver
without intra-comm:sockets, my coupling run has no problem.
with intra-comm:sockets, my coupling run has the error of “a serial participant” as above I mentioned. - mpirun -n 2 solidSolver
For this case, I must have intra-comm:sockets (otherwise some other preCICE error).
But my solidSolver hangs right after “preCICE: Connecting Primary rank to 1 Secondary ranks”
I wonder if you have any suggestion?
One point I worry is that our solver uses a communicator, ddm_comm. This communicator is a duplicate of MPI_COMM_WORLD when our solver program begins. My understanding for the reason of this design is to avoid conflicting with external libraries which might use the default MPI_COMM_WORLD. I am using preCICE FORTRAN interface of “call precicef_create” which doesn’t have the argument of the communicator. Any comment for this hanging problem?
That makes sense. I opened an issue regarding the error Error defining an intra-comm tag and running in serial · Issue #2025 · precice/precice · GitHub and the need to define the intra-comm in the first place Default intra-comm when MPI turned off · Issue #2026 · precice/precice · GitHub.
Exactly
port is the port for the connection between primary ranks.
enforce-gather-scatter allows you to use only the primary connection. Essentially disabling the use of further connections between ranks.
The documentation of the sockets attributes could be clearer.
As the error states, the intra-comm tag is only allowed for a participant running in parallel. This restriction is unnecessarily harsh. We may fix this in the next feature release.
This is most likely due to stale connectivity files. Remove all occurences of precice-run folders and you should be good to go. Another possiblity is that your secondary rank crashed.
This is not yet implemented as it wasn’t straightforward and there has been no demand for this feature. There have been recent pushes towards a more modern Fortran interface which supports this.
A pragmatic solution is to use preCICE with MPI_COMM_WORLD. If you run into issues, switch to <intra-comm:sockets/>. To my understanding, external libraries cannot change the MPI_COMM_WORLD and if something they do results in a deadlock, then your solver hangs anyway.
From a library perspective it is important to offer a possiblity for the user to pass a custom MPI Comm to enable cases where the library user splits the communicator. This is necessary for use-cases of the Multiple Instruction Multiple Data (MIMD) Model or for cases where the solver creates further custom groupings.
@fsimonis, thank you very much for all the information. They are very helpful to me.
Let me explain the reasoning here. From Benjamin’s dissertation, we have:
“It is challenging, since both participants possess, in general, different domain decompositions, which then also entail different decompositions of the coupling interface. Thus, for every rank, we need to identify which part of the coupling mesh it has to communicate to whom.”
Let me put down some language to start from:
- There are 2 things from the above quote: different domains and the coupling interface.
- Let’s consider the 3D case.
- According to Benjamin’s dissertation, the domain and its interface will be decomposed together. For a typical 3D FSI problem, for instance the perpendicular flap problem, this means the interior discretization, such as hexahedron elements, and the exterior discretization, such as the quadrilateral elements (sides of the hexahedrons), are decomposed together into the same domain.
- The surface integration of the pressure exerted on these exterior quadrilaterals will give the external nodal force.
My question is that if the pressure or the external nodal force calculation is not decomposed together with the interior hexa, but instead is done only on rank 0 process for solidSolver, how should I do the coding and let preCICE know?
- Because the coupling interface is not decomposed, there is no need to “identify which part of the coupling mesh it has to communicate to whom.” The solidSolver needs to ensure only rank 0 holds all the external forces. So the following item 2 and item 3.
- If rank.eq.0, then everything (on the coupling interface) exchanges on rank 0:
call precicef_create(solidSolverName, configFile, rank=0, commsize=10)
call precicef_set_vertices(the-coupling-interface-nodes) … - If rank.ne.0 then return. (basically do nothing since these non-root processes don’t participate the external nodal forces calculation).
- By using m2n:sockets, how can I ensure preCICE on the fluidSolver side sends all pressure to solidSolver rank 0?
In summary, my main point is: the coupling interface is not decomposed and is only treated on rank 0 (while the interior is decomposed, but it is not relevant because for FSI, preCICE is only responsible for the displacement and the force exchanges on the coupling interface.)
Could you open a new topic on discourse about your scenario?
Your last post has moved far form the original question regarding MPI support.